Intelligent Edge is a continually expanding set of connected systems and devices that gather and analyze data — close to the end users, the data, or both. Users get real-time insights and experiences, delivered by highly responsive and contextually aware apps. Unarguably, the Intelligent Edge provides analytics capabilities that were formerly confined to on-premises or cloud data centers.
The term “Intelligent Edge” or “Intelligence at the Edge” is used in many ways, but perhaps the best way to think of it is as a place where the action is. It’s a manufacturing floor, a building, a campus, a city, your house, a crop field, a wind farm, a power plant, an oil rig, a sports arena, a battlefield, in your car, in the sky, or under the sea. It’s everywhere everything is, and it’s where the “things” are in the Internet of Things (IoT).
Cloud-based AI has enabled on-demand business intelligence for enterprises and consumers alike. But to effectively deliver intelligence, AI must exist at the edge to benefit users with real-time analytics and actionable insights.
Why being close to user matters?
Evolution of data analytics from Cloud to Edge and further to Smart and Intelligent Edge, is guided by real consumer demands with supportive use cases justifying this architectural shift.
With technologies like 5G right around the corner, use of connected devices and applications of smart sensors are set to grow at an exponential rate. This not only will yield huge data volume, but at the same time will trigger an increasing demand for actionable insights within sub-milliseconds (or less) to guarantee real-time operations delivery by the controlling (IoT) devices.
Cisco Internet Business Solutions Group predicts: “50 billion connected devices by 2020”.
The use cases built around IoT are endless; devices are being used in homes to manage security, energy, watering and appliances. Factories are optimizing operations and costs through predictive maintenance. Cities are controlling traffic and applying IoT for public safety. Logistics companies are tracking shipments, doing fleet management and optimizing routes. Restaurants are ensuring food safety in fridges and deep fryers, retailer are deploying smart digital signage and implementing advanced payment systems — and the list goes on and on.
To cope with this challenge, “core” or “central” cloud alone cannot deliver services at the scale and speed expected in this era. Rather, support on the edge is going to be needed (in form of a separate cloud instance) to satisfy response time demands and to deliver superior user experience.
In this post, I elaborate the need of an edge focusing mainly on the AI/ML design strategy with edge playing a central role. So let’s get on to it.
AI/ML — Not just a Fancy Technology

The rate at which Artificial intelligence (AI) and machine learning (ML) are growing they won’t just be in our servers, smart phones, household gadgets and business software, but in every car, every building, every medical devices. We will rapidly reach a point where we cannot do business or get through the day without intelligence in everything we do. We can already see growth patterns emerging: Smart clouds are growing in prominence; smart apps are becoming ubiquitous. Predictive application programming interfaces (APIs) have sprung up in healthcare and logistics environments — not to mention the vast personalized marketing we all experience on the Internet.
Alright! let’s get back to our topic; it may be evident by now that a central cloud strategy alone cannot be scaled effectively to support stringent latency and performance requirements. With the explosion and exponential growth of IoT, offloading of certain critical functions, including the near and dearmachine intelligence,need to be rightfully done to a high-performing and low-latency cloud a.k.a theEdge.
AI capable Intelligent Edge
Machine learning is critical for the future of organizations everywhere, but driving business value from intelligent predictions requires connecting AI systems to business processes, wherever they are. For example, a manufacturer using machine learning-based defect detection requires low-latency results — without sending data out of the plant. This what necessitates presence of anintelligent Edge.
By creating intelligence at the edge, you reduce latency and security risks and at the same time improve user experience, thus making your business process more efficient.
Intelligence is built around Artificial Intelligence and Machine Learning, which drives off of raw data and user context. Processed through pre-trained models, this raw data get converted into actionable information allowing users to take real-time actions.
Although AI takes a central stage in this post, it is important to note that AI/ML just one piece of the puzzle besides other analytical and real-time applications, such as RTOS (real-time OS), database, data collection/aggregation, API engine, etc.
Before delving into the specifics we will look at different layers that usually make up a connectedIoT / Edge / Coresystem. Below figure shows a high level physical layout with the needed elements in a typical smart (IoT) devices and edge setup.
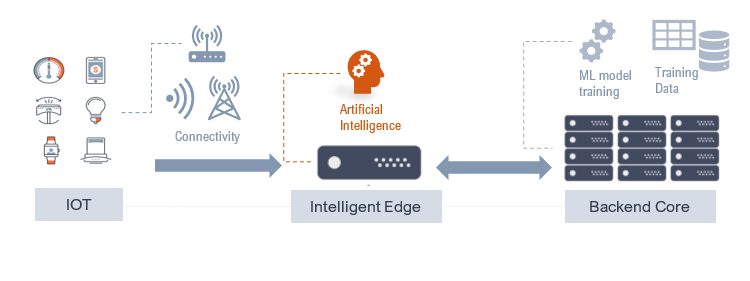
Why does Intelligence at the Edge matter?
Intelligence at the edge has important ramifications for the internet of things (IoT) and distributed networks. Being closer to the end users or data, it has proximity advantages over the core cloud in terms of response time, efficiency and security.
Using intelligent edge technology can help maximize business efficiency. Instead of sending data out to a data center or other third party, analysis is performed at the location the data is generated. Not only does this mean this analysis can be performed more quickly, but it also decreases the likelihood that the data will be intercepted or otherwise breached.
Even more intriguing are applications that combine edge computing and machine learning (ML) to enable new kinds of experiences and new kinds of opportunities in industries ranging from Mobile and Connected Home, to Security, Surveillance, and Automotive.
In later parts of this blog, you will see discussion on machine learning model training targeted for edge compute cloud and IoT devices alike. More specifically, I am going to discuss regularization & optimization techniques, while keeping in mind supervised Deep Learning.
Implementing such practices in your data science projects shall yield fruitful results. You can produce more productive machine learning models in terms of training and execution time, as well as minimize storage requirement.
Continuous Machine Learning System
It is a good practice to continuously monitor the incoming data and retrain your model on newer data if you find that the data distribution has deviated significantly from the original training data distribution. This architectural approach is described in the figure below.
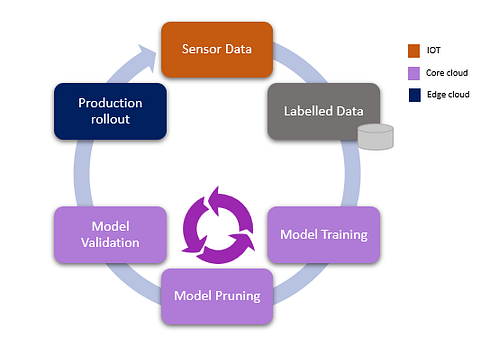
Machine Learning process architecture targeted for edge supported by multiple layers.
It delineates a typical machine learning process underscoring three distinct tiers, IoT, Core and Edge clouds. Let’s expand on it. First off, the labelled (training) data is secured separately from a singular or multiple resources, outside of the main process. This data is then fed into ML algorithms for model training, which (for practical reasons) takes place in back-end core. The core is poised to do the heavy lifting of model training due to (near) endless capacity and processing power availability. Once the model has reached acceptable accuracy, it is then deployed on the Edge to provide data insights and real-time inferences based on the data collected locally from the devices. Model training, followed by pruning (taking extra fat off) and validation goes through an iterative cycle to generate an optimal model before rolling into production.
This creates a closed loop system that incorporates the approach of taking user actions and then feeding them back into the data set for re-training. This entails new features or modified ground truth or both. Re-training on newer distribution helps in improving accuracy and increases capacity to handle wider range of data inputs.
In a typical multi-tiered, multi-segments system, you would pay attention to the sub-system characteristic. For example, Edge compute layer is supposed to have less storage and compute power comparing to the back-end cloud data center. High-performance and high throughput is expected of off the Edge to cater real-time traffic with low-latency and quick response time requirements. When it comes to re-training, tasks need to be carefully split between the Edge and the Core cloud to maintain business objectives and at the same time gain improvements in terms of better accuracy.
Training Process Life cycle
Notwithstanding the easy of creating and deploying ML models using popular scientific libraries there are specific optimization and pruning techniques required to produce a functional and productive model. This need is further compounded when it comes to model deployment on the edge cloud and/or end devices. In this post, I am picking up an example of a cloud aware application (such as, a virtual network function) running on the edge, nonetheless similar practice can be followed for training and deploying the model on IoT devices.
Below figure illustrate life cycle of a ML model exploiting continues learning methodology that involves above mentioned tiers, namely IoT, Edge and Core cloud.
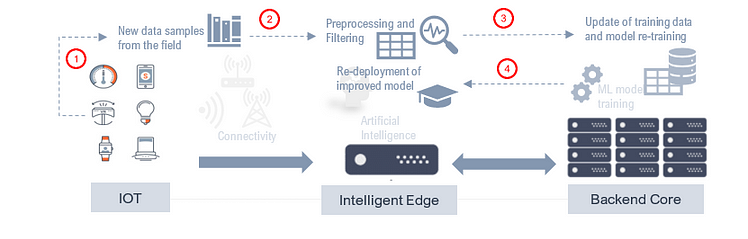
Feedback loop to improve AI capability base don new data samples.
Importantly, there is this notion of feedback loop and online model training/update stages. Pre-training and optimization takes place in a full-scale central cloud, utilizing its almost infinite power and space. By improving model capacity with more factual field data results in a better functioning model at run time. It can be shared over a number of (edge) devices by employing them for a number of tasks, with each device working in parallel.
Next let’s take a bit deeper dive into the technical aspects of supervised ML model optimization techniques, which are considered as compulsory model engineering exercises by many industry leaders.
Motivation and Strategy
Much like any process optimization, ML model optimization is targeted for achieving efficient run time performance when executed under resource constraints environment. The process involves step-wise, measurable improvements by applying a combination of optimization practices and algorithms.
It is important to have a good grasp on different optimization skills so that you can discern which technique and practices will yield the desired outcomes.
To define your ML strategy that is specifically applicable in resource constraint edge cases, below list can come handy:
- Select the right chip set with estimates for energy consumption and compute performance
- Storage requirements over time
- Latency and throughput requirements

- Understand your workload
- Understand your traffic patterns
- Understand your data growth
- Understand memory/storage requirements
- Hyper-parameters knowledge and tuning
- Re-use space and reduce storage overuse/overkill
- Train and save (at core), transfer (model) and load (at edge)
- Containerization of AI services — Well orchestrated and manageable
- Reproducible and secure pipelines (such as using kubeflow)
Benefits
Mmodel optimization is necessary for a number of reasons and some of them are highlighted as under:
- Less resources required: Deploying models to edge devices with restrictions on processing, memory, or power-consumption. For example, mobile and Internet of Things (IoT) devices.
- Efficiency: Reduced model size can help improving productivity, especially when deployed on the Edge.
- Latency: there’s no round-trip to a server, adherence to compliance
- Privacy: no data needs to leave the device or edge gateway, hence better security
- Connectivity: an Internet connection isn’t required for business operation
- Power consumption: Matrix multiplication operations require compute power. Less neurons means less power consumption.
Techniques
The idea is to craft engineered models that are more efficient in terms of speed, memory and storage. In the next few sections I will go through some of the widely used techniques in the industry for creating optimized deep learning models. So let’s get started!
1. Pruning
Pruning describes a set of techniques to trim network size (by nodes not layers) to improve computational performance and sometimes resolution performance. The gist of these techniques is removing nodes from the network during training by identifying those nodes which, if removed from the network, would not noticeably affect network performance (i.e., resolution of the data).
Even without using a formal pruning technique, you can get a rough idea of which nodes are not important by looking at your weight matrix after training; look weights very close to zero — it’s the nodes on either end of those weights that are often removed during pruning.
Pruning neural networks is an old idea going back to 1990 (with Yan Lecun’s optimal brain damage work) and before.
The idea is that among the many parameters in the network, some are redundant and don’t contribute a lot to the output.
If you could rank the neurons in the network according to how much they contribute, you could then remove the low ranking neurons from the network, resulting in a smaller and faster network.
Pruning Algorithms
By applying a pruning algorithm to your network during training, you can approach optimal network configuration.
The ranking of neurons can be done according to the L1/L2 mean of weights, their mean activations, the number of times a neuron wasn’t zero on some validation set, and other creative methods.
After the pruning, the accuracy will drop (hopefully not too much if the ranking clever), and the network is usually trained more to recover.
2. Dimensionality Reduction
When dealing with real world problems we often deal with high dimensional data that can cross million of data points. Depending upon your algorithm selection, techniques like PCA and RFE can prove to be quite useful in reducing data dimensions and hence model’s space requirements.
Although I am mentioning it here, however, it is not recommended for neural network based learning algorithms. Other techniques, such as the one described above and the ones in forth coming sections are more suitable for optimizing deep learning models.
2. Quantization
Quantization techniques are particularly effective when applied during training and can improve inference speed by reducing the number of bits used for model weights and activations. For example, using 8-bit fixed point representation instead of floats can speed up the model inference, reduce power and further reduce size by 4x.
We will look at several techniques and useful tips as we move on with our discussion.
- Reduce parameter count with pruning and structured pruning. Practically setting the neural network parameters’ values to zero, thus creating a sparse neural net (matrix). Sparse matrices tend to yield better compression resulting in overall model size reduction.
- Reduce representational precision with quantization. Quantizing deep neural networks uses techniques that allow for reduced precision representations of weights and, optionally, activations for both storage and computation. It is found that weight pruning when combined with quantization, results in compound benefits.
- Update the original model topology to a more efficient one with reduced parameters or faster execution. For example, tensor decomposition methods and distillation.
4. Regularization
One of the most common problem data science professionals face is to avoid overfitting. Avoiding overfitting can single-handedly improve your model’s performance. L1 and L2 (weight decay) are the most common types of regularization. These update the general cost function by adding another term known as the regularization term. Concretely;
Cost function = Loss (say, binary cross entropy) + Regularization term
the weight matrices W to be reasonably close to zero. So one piece of intuition is maybe it set the weight to be so close to zero for a lot of hidden units that’s basically zeroing out a lot of the impact of these hidden units.
We can think of it as zeroing out or at least reducing the impact of a lot of the hidden units so you end up with what might feel like a simpler network. It turns out that what actually happens is they’ll still use all the hidden units, but each of them would just have a much smaller effect.
But you do end up with a simpler network and as if you have a smaller network that is therefore less prone to overfitting.
5. Hyper-parameters Tuning
By tuning hyper-parameters efficient networks can be engineered which will result in superior run time performance when put under resource constraining situations, like on an IoT device or MEC.
Some of the users’ favourite are:
Neural Network depth — Concretely, depth of a NN and the number of neurons per hidden layer enhance model’s capability to work with more complex decision boundaries. The selection of number of neurons per layer and number of layers constitute what’s called the network architecture. There is no hard and fast rule when it comes to decide on the hidden layer(s) dimensions; rather your architectural choices will be based on the empirical results obtained from different combinations. Typically, you will treat the number of Hidden layers as a tune able hyper-parameter and use it during the forward pass.
Drop out ratio — Dropout is a technique to fight overfitting and improve neural network generalizatio. It is one of the most interesting types of regularization techniques and most frequently used in the field of deep learning.
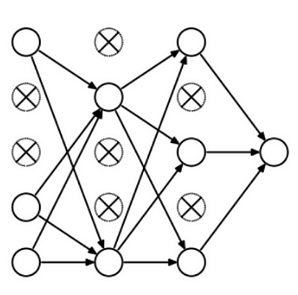
It is almost always efficient to reduce the size of a layer by dropping (zeroing out weights) some of the neurons randomly.
Dropout is also a defensive mechanism against model over-fitting. At every iteration, it randomly selects some nodes and removes them along with all of their incoming and outgoing connections. The dropout ratio is a hyper parameter that controls the zeroing out of neurons/weights and supported by all major ML libraries such as Keras. The value is normally set between 0.25–0.50.
6. Hardware Acceleration
At its core, neural networks are multi-dimensional arrays (matrices or tensors) which operate on mathematical operations like addition and multiplication. Specialized hardware such as FPGA , TPU or GPU rapidly manipulate and alter memory to accelerate the overall process, such as model training and its execution.
Edge TPU is Google’s purpose-built ASIC designed to run AI at the edge. It delivers high performance in a small physical and power footprint, enabling the deployment of high-accuracy AI at the edge.
Other solutions like AI2GO from Xnor AI provide pre-built, purpose built models that can run autonomously on small inexpensive devices including Raspberry Pi with no connection to Internet or central cloud is needed.
7. Lite-weight Framework
In May 2017 Google introduced TensorFlow Lite for mobile edge devices development. It is designed to make it easy to perform machine learning at the edge, instead of sending data back and forth to a server. TensorFlow Lite works with a huge range of devices, from tiny microcontrollers to powerful mobile phones.
Putting it all together — Pipelines
Finally, you would want to plug / stitch together all the pre-processing and data manipulation as part of the model creation. For effective data engineering and model training, pipelines are commonly used of such tasks.
Collectively, these data pipelines constitute a workflow that governs processing logic and cut across different boundaries in a typical ML project.
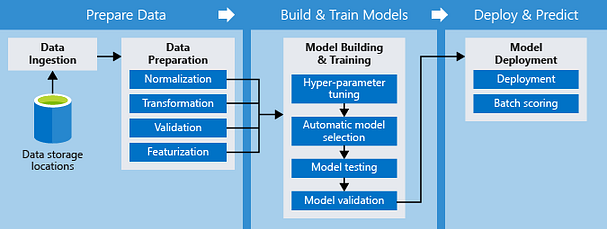
Courtesy of Microsoft Azure website.
Multiple options are available, such as Kubeflow, AutoML, Azure ML Pipelines.
Purpose built Frameworks
Frameworks like Learn2Compress from Google, generalizes the learning by incorporating several state-of-the-art techniques for compressing neural network models. It takes as input a large pre-trained TensorFlow model provided by the user, performs training and optimization and automatically generates ready-to-use on-device models that are smaller in size, more memory-efficient, more power-efficient and faster at inference with minimal loss in accuracy.
References
[1] The intelligent Edge is in your future — https://www.cisco.com/c/en/us/solutions/enterprise-networks/intelligent-edge.html
[2] Western Digital — https://blog.westerndigital.com/machine-learning-edge-devices/
[3] TensorFlow Pruning API — https://medium.com/tensorflow/tensorflow-model-optimization-toolkit-pruning-api-42cac9157a6a
[4] TensorFlow Lite — https://www.tensorflow.org/lite/guide
[5] https://ai.googleblog.com/2018/05/custom-on-device-ml-models.html
[6] https://heartbeat.fritz.ai/how-to-fit-large-neural-networks-on-the-edge-eb621cdbb33
[7] https://www.einfochips.com/blog/ml-at-the-edge-will-help-unleash-the-true-potential-of-iot/
[8] https://jacobgil.github.io/deeplearning/pruning-deep-learning
[9] Edge TPU — https://cloud.google.com/edge-tpu/
See also
